
I am a DIY-er (do it yourself-er). There was always a home project to work on; plumbing, electrical, carpentry. You name it. I knew how to do these things correctly, but it always took so incredibly long to finish. I had all the tools I needed, but they were in my toolbox or in a cabinet in the garage.
The reason for projects lasting forever was I was spending a huge amount of time going through my toolbox or going back and forth to the garage to get the tool I needed when I needed it. How did I make myself more efficient? I bought a toolbelt. Now I have all the tools that I use 90% of the time within reach. What a difference it has made.
When it comes to dispersion modeling, my biggest pet peeve is having all my information and tools scattered all over the place. I have to go one place for data to run one program, then go somewhere else for data for a second program, and then another place for a third program, and so on and so on. I like all my stuff together in one place. Not pristine perfect rows and columns, but just in one place, reasonably neat.
Using a database for your dispersion modeling projects is like having a toolbelt.
Know Your Data
You really need to know your data. Before that, you really need to know your process, step by step. What are all the steps involves to complete a task or a project and what information is needed at each step? If you have a result, product, or deliverable at the end of the step, what is required to like? Most things don’t happen accidentally. Something had to go in for something to come out.
What is it so important to know your process and your data? When you segment your data into multiple tables, you need to know what relationships exist between your tables and the fields in those tables. In a database platform, you can create and enforce relationships. Relationships can provide some of the rules of what determines good data from potentially useless bad data.
A simple example would be, AERMOD recognizes specific source types, e.g. POINT, AREA, VOLUME, etc. When building your table to store your sources, you will probably want to keep track of the source type. To prevent unrecognizable source types from creeping into your database, such as PIONT, AERA, or VOLEUM, you can create a second table that contains only the source types that are valid. To enforce this rule, set up a relationship between the source type fields in the two tables. Once the relationship is set up, the database platform will not allow this type of bad data to go into your source table.
Relationships not only keep your data clean, but also significantly speed up queries when using values from related fields. Rather than reading through each record of each table to compare values, the relationships you create also create indexes behind the scenes. Like the indexes in a book, an index allows the database platform to go right to the data that meets the criteria specified in your queries. You can set other indexes on your data, but that’s a bit more complicated and beyond keeping things simple.
Using Joins
Relationships help multiple table queries run faster; much faster. We talked about queries with one table (http://www.naviknow.com/2018/07/18/using-databases-simple-queries/) and one table with calculations (http://www.naviknow.com/2018/07/25/using-databases-calculations-with-queries/), but how do you write a multi-table query? The answer is you use JOINs.
Different Kinds of Joins
There are five kinds of joins. Each produces a different result.
INNER JOIN: An INNER JOIN returns records with field values in common to both tables.
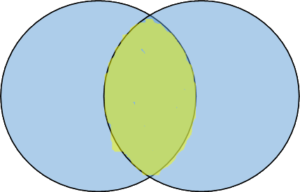
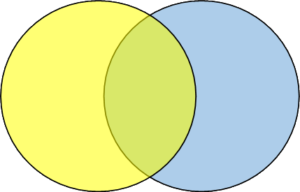
LEFT OUTER JOIN: A LEFT OUTER JOIN returns all the records from the left table and records with field values in common to both tables.
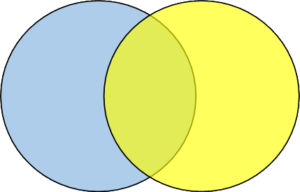
RIGHT OUTER JOIN: A RIGHT OUTER JOIN returns all the records from the right table and records with field values in common to both tables.
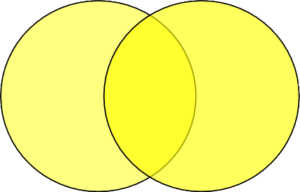
FULL OUTER JOIN: A FULL OUTER JOIN returns all the records from the both table and field values in common to both tables.
CROSS JOIN: A CROSS JOIN returns the combination of each row of one table with the each row of the second table. The number of records returned is the number of records in the first table multiplied by the number of records in the second table.
All of the JOIN types, except for the CROSS JOIN, require an ON clause to accompany the JOIN declaration.
INNER JOIN Examples
Suppose we have two database tables. One table lists all of our emission sources (tblEPN_Source) and the other contains a list of all the emission rates for all air contaminants for all of our sources (tblEPN_Emissions). One field that would be in common to the two tables would be the source identifier, which we will call EPN (this is an artifact of the legacy naming convention used in Texas air quality permitting and emissions inventories. It is short for Emission Point Number. Each regulatory entity will have its own naming convention.)
Since every source in tblEPN_Emissions should be listed in tblEPN_Source, we can set up a relationship between the two tables based on the EPN field that will enforce that rule. This can be accomplished by executing a few SQL statements (which we are not getting into just yet) or using the GUI for your database platform (a whole lot easier). The graphic representation should look something like this:
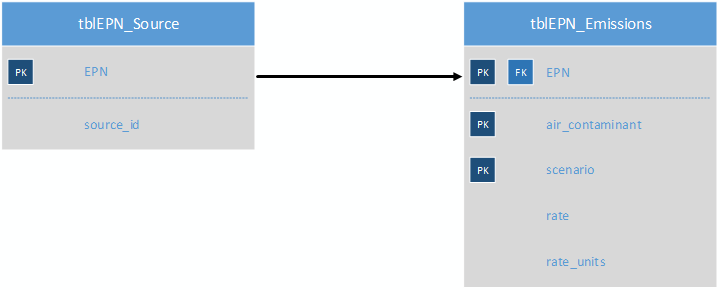
If you wanted to know which sources emit specific air contaminants, you would write a SQL statement that looks like this:
SELECT tblEPN_Source.EPN, tblEPN_Emissions.air_contaminant FROM tblEPN_Source INNER JOIN tblEPN_Emissions ON tblEPN_Source.EPN = tblEPN_Emissions.EPN WHERE (tblEPN_Emissions.air_contaminant='AMMONIA' OR 'BENZENE') AND (tblEPN_Emissions.scenario='ROUTINE')
Notice how the query will return data contained in both tables based on the field values in common. Also, notice that the criteria for which records to return can be from either table (see the WHERE clause).
Joins can be used for as many tables as your query requires.
In addition to the result from about, suppose you want the value of the air quality standard for the air contaminants to be included, too. You have a database table tblAirStandards that lists that information. That table has a field name air_contaminants which is in common with the same named field in tblEPN_Emissions. Every air contaminant your sources emit should have an air quality standard (or else why would you model). we can set up a relationship between the two tables based on the air_contaminant field that will enforce that rule. Graphically, the data model would look like this:
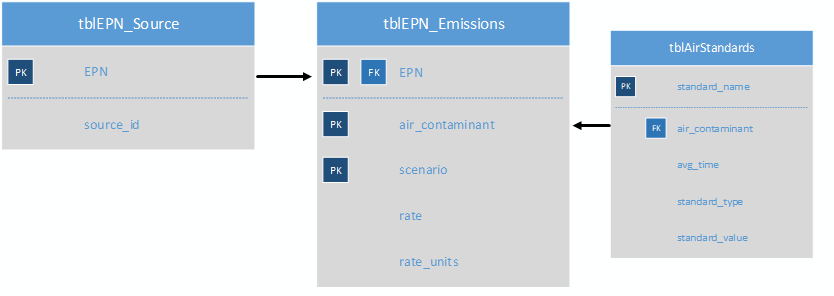
To return the list of sources with the most stringent standards, your SQL statement might look something like this:
SELECT tblEPN_Source.EPN, tblEPN_Emissions.air_contaminant FROM tblEPN_Source INNER JOIN tblEPN_Emissions ON tblEPN_Source.EPN = tblEPN_Emissions.EPN INNER JOIN tblAirStandards ON tblAirStandards.air_contaminant=tblEPN_Source.air_contaminant WHERE (tblAirStandards.standard_value < 100) AND (tblEPN_Emissions.scenario='ROUTINE')
Notice how the next table is included by just stringing on another JOIN…ON clause. When you are designing your database, you really should put a good deal of thought into what kind of information you want to pull from it and how all the data are related. Just like your toolbelt, consider the tools you use most when loading it up because you can’t put everything into it.
Summary
In this article, we emphasized that data has to have structure and rules before you start populating your database table. The structure and rules are enforced by creating relationships between fields making up the tables. Also, the relationships, besides keeping out bad data, can speed up query execution in a very big way depending upon how many records need to be searched through. The more records involved, the bigger the impact these relationships have.
To build queries to access data from multiple table, you use joins. There are five kinds of joins: INNER, LEFT OUTER, RIGHT OUTER, FULL OUTER, and CROSS. The first four require that tables involved in the join, have a field value in common.
When you build your database, put a goodly amount of thought into how the bits and pieces are related to each other and how they fit together and what and how you intend to access data from it.
If you found this article informative, there is more helpful and actionable information for you. Go to http://learn.naviknow.com to see a list of past webinar mini-courses. Every Wednesday (Webinar Wednesday), NaviKnow is offering FREE webinar mini-courses on topics related to air quality dispersion modeling and air quality permitting. If you want to be on our email list, drop me a line at [email protected].
One of the goals of NaviKnow is to create an air quality professional community to share ideas and helpful hints like those covered in this article. So if you found this article helpful, please share with a colleague.